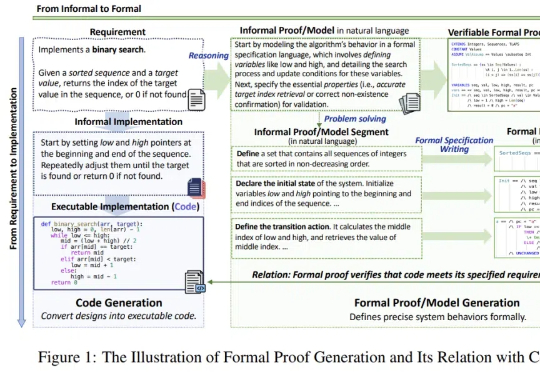
7B级形式化推理与验证小模型,媲美满血版DeepSeek-R1,全面开源!
7B级形式化推理与验证小模型,媲美满血版DeepSeek-R1,全面开源!随着 DeepSeek-R1 的流行与 AI4Math 研究的深入,大模型在辅助形式化证明写作方面的需求日益增长。作为数学推理最直接的应用场景,形式化推理与验证(formal reasoning and verification),也获得持续关注。
来自主题: AI技术研报
6418 点击 2025-03-09 10:31
 搜索
搜索
随着 DeepSeek-R1 的流行与 AI4Math 研究的深入,大模型在辅助形式化证明写作方面的需求日益增长。作为数学推理最直接的应用场景,形式化推理与验证(formal reasoning and verification),也获得持续关注。
仅仅过了一天,阿里开源的新一代推理模型便能在个人设备上跑起来了!昨天深夜,阿里重磅开源了参数量 320 亿的全新推理模型 QwQ-32B,其性能足以比肩 6710 亿参数的 DeepSeek-R1 满血版。

让人感到非常费解的是,在这些媒体口中如此“王炸”的 AI 突破,在海外几乎没有什么讨论,这与 DeepSeek 墙内开花墙外香,海外各路 AI 大神们甘当自来水疯狂吹爆的现象形成了巨大的反差
如果根据AI自媒体们的标题来看,昨天全世界AI圈应该无人存活,因为他们又被“炸”了。

编辑注:今天上线的Manus引发了全网的 Agent 热潮,Manus 背后的产品团队——Monica.im 的产品团队也引起了大家的关注。Manus产品负责人张涛在 2 月份曾经有过一次公开分享,解读 DeepSeek R1 成功背后的技术进步和产品思路,从中可以一窥 Manus 的部分解题思路。

又一个「DeepSeek 王炸组合」,来了。2 月 28 日,两个国民级应用,百度文库和百度网盘,全量接入了 DeepSeek-R1 满血版。

挤牙膏的新款 iPad Air 和 iPad 果然只是开胃小菜,今天苹果为我们带来了更有看点的 MacBook Air 和 Mac Studio 更新。

「某某公司租的机器狗,都累没电趴窝了。」
在 R1 推理模型大火之后,全民接力集成 DeepSeek,有硅基流动这样的大模型云服务平台、有腾讯元宝这样的 Chatbot,甚至微信这样的顶流。但是,AI 图片类产品却鲜少有接入 DeepSeek R1 的新闻,而从 DeepSeek-R1 发布到 Krea 宣布上线新功能仅仅 10 天,这个反应应该是图像产品中最快的。

随着 DeepSeek 问世,从春节至今,和AI有关的资讯与讨论已经让人有些疲劳。然而,相关讨论大都聚焦在产业、投资和技术方面,其中不乏优质信息,但仍缺少一个重要的视角——作为普通用户,我们如何看待并使用AI。